Ten artykuł to zapis pierwszej części tego procesu: pomiar, diagnoza i program zmian wdrożony w trzy dni. Część druga, z wynikami po 30, 60 i 90 dniach, wyjdzie około sierpnia 2026.
01 / TL;DR Najważniejsze wnioski z audytu.
Stan na lipiec 2026:
- 3 lipca 2026 uruchomiłem 18 promptów w trzech modelach z wyszukiwaniem (Claude Sonnet z web search, Gemini 2.5 Flash z groundingiem, GPT-5 z web search) - łącznie 54 odpowiedzi. To punkt zero, zmierzony świadomie przed jakimikolwiek zmianami na stronie.
- Widoczność mojej marki we wszystkich promptach: Claude 4/18 (22%), Gemini 3/18 (17%), GPT-5 2/18 (11%).
- Pytania brandowe: 6/6 (100%) - każdy z trzech modeli wie, kim jestem i co robię. Pytania z kategorii AI Visibility: 0/12 - w kategorii, którą sam sprzedaję, modele cytują dziś innych.
- W dniach 3-5 lipca wdrożyłem na stronie kilkanaście zmian pod cytowalność przez modele: od kapsuł treści i FAQPage schema, przez llms.txt i jawne ceny, aż po hub case studies.
- Od teraz co poniedziałek automatyczny tracker uruchamia tę samą baterię promptów. Wyniki po 30/60/90 dniach opublikuję w części drugiej - niezależnie od tego, jak wyjdą.
02 / Punkt wyjścia Dlaczego zbadałem sam siebie.
W audycie AI Visibility, który wykonuję dla klientów, pierwszym krokiem jest zawsze pomiar stanu obecnego. Bez punktu zero nie da się później udowodnić, że którakolwiek zmiana zadziałała, więc baseline robi się przed programem zmian, a nie po nim. Skoro tę metodykę dostaje każdy klient, uczciwie było przepuścić przez nią własną stronę.
Kontekst czasowy jest tu istotny jako fakt. Obecna wersja strony żyje od maja 2026, czyli w momencie pomiaru miała dwa miesiące. Usługa AI Visibility jest w mojej ofercie od czerwca 2026. Baseline zrobiłem 3 lipca, świadomie przed jakąkolwiek optymalizacją, ponieważ chciałem mieć czysty punkt odniesienia, a nie pomiar zanieczyszczony zmianami, które już zdążyły zadziałać albo nie.
Jest jeszcze jeden powód, dla którego ten pomiar był potrzebny. W rozmowach z klientami regularnie ostrzegam przed mechanizmem, w którym marka jest znana modelom, a mimo to modele nie polecają jej w pytaniach kategorii. Modele odpowiadają na pytania typu „kto w Polsce robi X" ze źródeł zewnętrznych i treści kategorii, a sama rozpoznawalność marki nie wystarcza, żeby znaleźć się w takiej odpowiedzi. Postanowiłem zmierzyć ten mechanizm na sobie.
03 / Metoda 18 promptów, 3 modele, 5 klastrów.
Metoda jest na tyle prosta, że możesz powtórzyć ją u siebie w jedno popołudnie.
Przygotowałem 18 promptów podzielonych na 5 klastrów tematycznych, które pokrywają moją ofertę i sposób, w jaki potencjalny klient mógłby o nią pytać: AI Visibility/GEO (4 prompty), agenty AI w marketingu (5), Meta Ads i UGC (4), szkolenia AI (3) oraz pytania brandowe wprost o mnie i moją domenę (2).
Każdy prompt uruchomiłem w trzech modelach z dostępem do wyszukiwania: Claude Sonnet z web search, Gemini 2.5 Flash z groundingiem (podpięciem wyników wyszukiwania Google) oraz GPT-5 z web search. Wybrałem warianty z wyszukiwaniem celowo, ponieważ to one odpowiadają na komercyjne pytania świeżymi źródłami, a nie wyłącznie wiedzą z treningu. Łącznie dało to 54 odpowiedzi.
Metryka była zerojedynkowa: czy odpowiedź lub cytowane w niej źródła zawierają markę, czyli którekolwiek z: Kamil Sławiński, kamilslawinski.com, WAYSTAR. Równolegle zarchiwizowałem baseline z Google Search Console (impresje i pozycje) oraz baseline logów botów AI odwiedzających stronę, żeby w części drugiej móc zestawić widoczność w odpowiedziach z tym, co realnie dzieje się w ruchu i crawlingu.
04 / Wyniki Punkt zero: brand 100%, kategoria 0%.
Zacznę od tego, co w baselinie wyszło mocno. Klaster brandowy zamknął się wynikiem 6/6, czyli 100%. Każdy z trzech modeli zapytany „kim jest Kamil Sławiński" albo „co wiesz o kamilslawinski.com" odpowiada poprawnie i z konkretami. Claude z web search wymienia mnie przy pytaniu o agenta AI prowadzącego kampanie Meta Ads w Polsce oraz przy pytaniu o kampanie UGC. Mój artykuł o Meta Ads MCP jest cytowany przez ChatGPT. Widoczność jest - w tych obszarach, w których od tygodni istnieją moje treści.
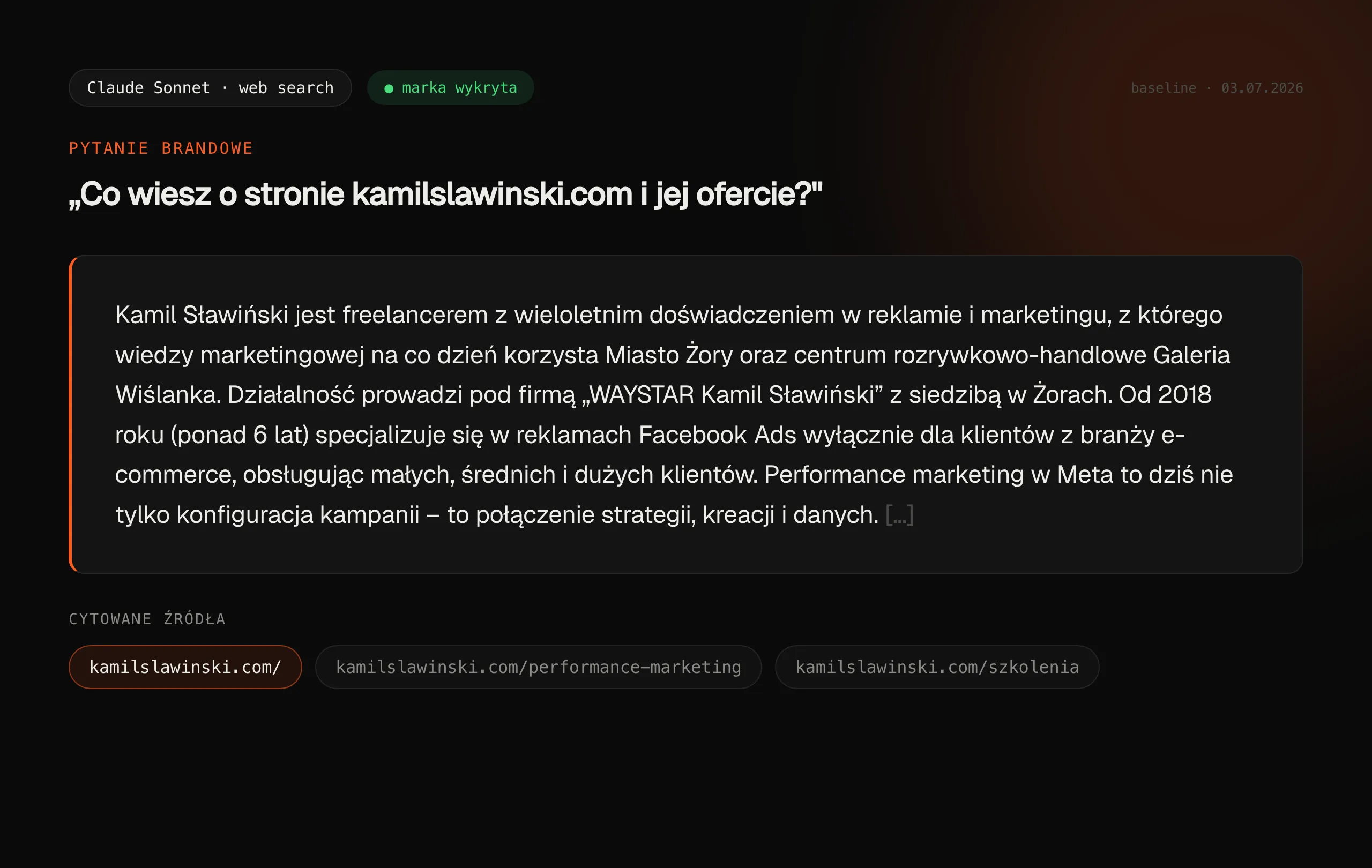
Pełne liczby per model, dla wszystkich 18 promptów:
| Model | Wynik | Procent |
|---|---|---|
| Claude Sonnet (web search) | 4/18 | 22% |
| Gemini 2.5 Flash (grounded) | 3/18 | 17% |
| GPT-5 (web search) | 2/18 | 11% |
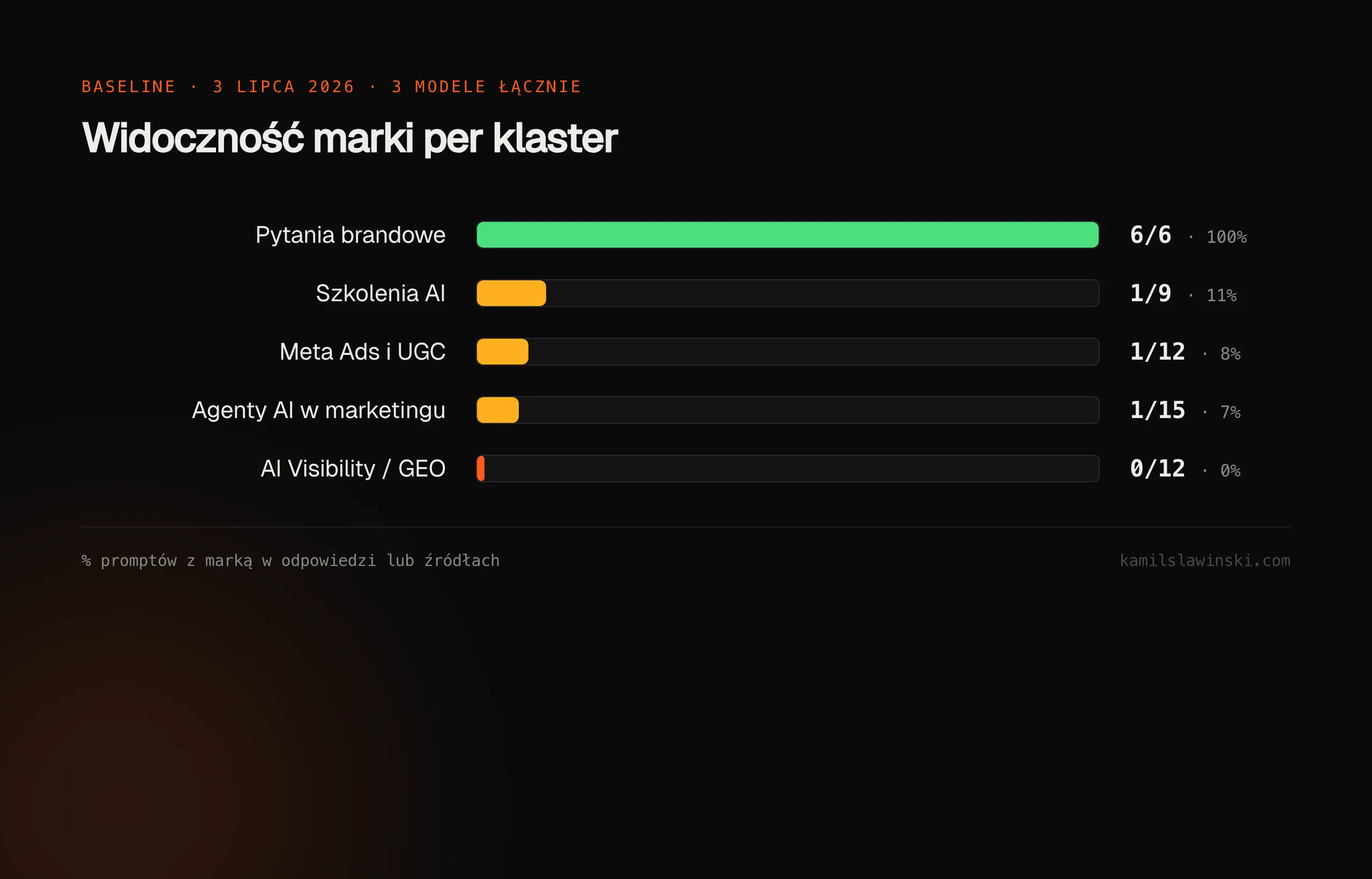
I per klaster, we wszystkich trzech modelach łącznie:
| Klaster | Wynik |
|---|---|
| Pytania brandowe | 6/6 (100%) |
| Agenty AI w marketingu | 1/15 |
| Meta Ads i UGC | 1/12 |
| Szkolenia AI | 1/9 |
| AI Visibility / GEO | 0/12 |
Ta ostatnia linijka to teza całego artykułu. W klastrze AI Visibility, czyli w mojej flagowej usłudze, marka nie pojawiła się w żadnej z 12 odpowiedzi. Modele zapytane, kto w Polsce robi AI Visibility czy GEO, cytują dziś podmioty takie jak Whites Agency, Deloitte Polska czy aivisible.pl - często za samo posiadanie treści o GEO, bo kategoria jest w Polsce młoda i płytka.
Rozbieżność między 100% w klastrze brandowym a 0% w klastrze kategorii to dokładnie ten mechanizm, przed którym ostrzegam klientów. Modele odpowiadają na pytania kategorii ze źródeł kategorii, więc marka bez treści w danej kategorii jest dla retrievera (mechanizmu, który wyszukuje i wybiera źródła do odpowiedzi) niewidoczna, nawet jeśli sam model doskonale wie, kim ta marka jest. Moja strona miała w momencie pomiaru dwa miesiące, a usługa AI Visibility była w ofercie od miesiąca - treści kategorii po prostu jeszcze nie zdążyły powstać i zostać zaindeksowane. Ekspertyza w tej dziedzinie polega na umiejętności zmierzenia, zdiagnozowania i naprawienia tego stanu, i to jest proces, który opisuję dalej.
Z baseline'u wyszła jeszcze jedna obserwacja, która mnie zaskoczyła. Przy prompcie o polecenie konkretnego specjalisty Meta Ads Claude odmawia polecania osób z nazwiska i zamiast tego uczy, jak samodzielnie zweryfikować kandydata. Gemini i GPT-5 polecają śmiało, z nazwiskami i domenami. Modele różnią się więc polityką polecania, a z odpowiedzi Gemini i GPT-5 widać, że soliści z dobrą własną domeną są w takich odpowiedziach cytowani. To ważny sygnał dla każdego, kto myśli, że w odpowiedziach AI mieszczą się wyłącznie duże agencje.
05 / Wdrożenie Co dokładnie zmieniłem w trzy dni.
Program zmian przeprowadziłem w dniach 3-5 lipca 2026, bezpośrednio po baselinie. Poniżej te wdrożenia, które według mnie mają największy wpływ na cytowalność, każde z krótkim wyjaśnieniem, dlaczego działa na retriever.
Kapsuły treści. Przy każdej usłudze dodałem samowystarczalny akapit-definicję, który da się zacytować w oderwaniu od reszty strony. Retriever często wyciąga z dokumentu pojedynczy fragment, więc akapit, który sam z siebie odpowiada na pytanie (co to jest, dla kogo, ile kosztuje), ma większą szansę trafić do odpowiedzi niż myśl rozciągnięta na trzy sekcje.
FAQPage schema 1:1 z widoczną treścią. W serwisie jest teraz około 75 pytań, wszystkie jako nagłówki H3, i wszystkie odwzorowane w danych strukturalnych FAQPage. Zasada jest twarda: w schema nie ma ani jednego pytania, którego nie widać na stronie, ponieważ rozjazd między znacznikami a treścią to prosty sposób na utratę zaufania crawlera.
Nagłówki-pytania w wariancie hybrydowym. Sekcje, które odpowiadają na realne pytania użytkowników, dostały pytające H2, np. „Ile kosztuje AI Visibility i jaki zakres wybrać?", „Dla kogo jest AI Visibility?" albo „Czy korzystanie z MCP nie naraża konta na bana?". Komercyjne prompty to w dużej mierze pytania, więc nagłówek pokrywający się z pytaniem użytkownika ułatwia retrieverowi dopasowanie fragmentu do zapytania.
Jawne ceny na stronach usług. Pytania cenowe to najczęstsze komercyjne prompty, a strona bez ceny nie ma czego zaoferować modelowi, który na takie pytanie odpowiada. Tam, gdzie cennik jest jawny, jest teraz podany wprost.
llms.txt i llms-full.txt. Pierwszy plik to ręcznie napisany skrót oferty przeznaczony dla modeli, drugi to pełna baza treści serwisu generowana automatycznie co noc. Do tego agent.json i agent-card.json. To wciąż młode standardy i część botów je ignoruje, natomiast koszt utrzymania jest niski, a plik daje modelom skondensowane źródło zamiast zmuszania ich do składania obrazu z kilkunastu podstron.
Hub /case-study/. Sześć case studies z wynikami zebrałem w jednym linkowalnym miejscu pod adresem /case-study/, z danymi strukturalnymi CollectionPage. Wcześniej breadcrumby i stopka celowały w sekcję na stronie głównej, więc dowody rozpraszały się po serwisie zamiast wzmacniać jeden adres, który model może zacytować jako „portfolio z wynikami".
Poprawność językowa jako sygnał ekspercki. W całym serwisie obowiązuje teraz forma „agenty AI" (rodzaj męskorzeczowy, jak boty czy roboty), a nie „agenci". Łącznie 22 poprawki, włącznie z H1. Drobiazg, ale w młodej kategorii, w której połowa polskich treści kalkuje formy z angielskiego, konsekwentna poprawność odróżnia źródło pisane przez specjalistę od tekstu generowanego hurtowo.
Usunięcie treści-sieroty. Testowy artykuł sprzed startu strony wyindeksowałem przez 410 Gone (kod odpowiedzi serwera oznaczający, że zasób został trwale usunięty). Stara, przypadkowa treść w indeksie to szum, który może trafić do odpowiedzi zamiast właściwej strony.
Synchronizacja danych strukturalnych. Person z atrybutem sameAs spinającym moje profile, BlogPosting na artykułach, BreadcrumbList w całym serwisie. Do tego w artykułach TL;DR w punktach z datownikiem oraz tabele porównawcze tam, gdzie treść na to zasługuje (np. MCP kontra własny agent). Ustrukturyzowane fragmenty z jasną datą to dla retrievera najłatwiejszy materiał do cytowania.
Równolegle strona przeszła przebudowę wizualną hero i systemu świateł, ale to temat na inną okazję i na wyniki baseline'u nie ma wpływu.
06 / Granice Czego nie zmieniłem i dlaczego.
Program zmian miał też świadome granice i one są równie ważne jak lista wdrożeń.
Mocne tezy marki zostały tezami. Nagłówki-pytania dostały tylko te sekcje, które faktycznie odpowiadają na pytania użytkowników, natomiast zamiana wszystkiego na pytania osłabiłaby stronę. Strona usługowa ma również przekonywać człowieka, który na nią trafi, a tekst złożony w całości z pytań i odpowiedzi czyta się jak dokumentację, nie jak ofertę eksperta z własnym zdaniem. Optymalizacja pod retriever, która psuje stronę dla człowieka, jest złą optymalizacją, ponieważ ostatecznie to człowiek podejmuje decyzję o współpracy.
Nie ruszyłem też niczego, co wymagałoby naginania faktów. Żadnych dopisanych na siłę fraz kategorii tam, gdzie nie pasują, żadnych sztucznych wzmianek o konkurencji dla samego kontekstu porównawczego.
07 / Pomiar Jak to mierzę dalej.
Baseline bez dalszego pomiaru byłby tylko ciekawostką, więc od lipca działa automatyczny tracker, który w każdy poniedziałek uruchamia tę samą baterię 18 promptów w tych samych trzech modelach i zapisuje wyniki. Interesuje mnie trend per model i per klaster, a nie pojedyncze odpowiedzi, ponieważ modele potrafią na to samo pytanie odpowiedzieć różnie w różnych sesjach i dopiero seria pomiarów pokazuje realną pozycję.
Do tego dochodzi Google Search Console i logi botów AI, których baseline też mam zarchiwizowany. Przegląd wyników planuję po 30, 60 i 90 dniach od wdrożenia zmian.
Kolejny front, który dopiero przede mną, to źródła zewnętrzne: profil na Clutch, publikacje w polskich mediach branżowych i regularne treści na blogu. Baseline pokazał, że modele w młodej kategorii cytują tych, którzy mają treści kategorii - a treści na własnej domenie to tylko część tego równania.
Nie wiem jeszcze, które z wdrożonych zmian zadziałają, a które okażą się bez znaczenia - dlatego mierzę co tydzień. Wyniki opublikuję niezależnie od tego, jak wyjdą.
08 / Dla kogo Ten sam proces u klienta.
Wszystko, co opisałem wyżej, to jest dokładnie warsztat, który wykonuję komercyjnie. Baseline promptów w trzech modelach, analiza per klaster, diagnoza luk i program zmian z pomiarem - w wariancie Snapshot dostajesz szybką diagnozę w 48 godzin, w Deep Audit pełny audyt z roadmapą na 90 dni. Różnica jest taka, że u klienta zestaw promptów budujemy razem na warsztacie, pod jego buyer persony i customer journey, a nie pod moją ofertę.
Największy sens ma to w firmach, w których klient prowadzi dłuższy research przed zakupem: porównuje opcje, pyta o opinie, sprawdza ekspertyzę dostawcy. Jeśli po tym artykule chcesz sprawdzić, jak modele odpowiadają na pytania z Twojej kategorii, możesz zacząć od powtórzenia mojej metody z sekcji 03 u siebie. W razie pytań o pełny audyt - jestem do dyspozycji.
09 / FAQ Najczęstsze pytania.
Czym AI Visibility (GEO) różni się od SEO?
Klasyczne SEO optymalizuje stronę pod pozycję w wynikach Google. AI Visibility (GEO, Generative Engine Optimization) optymalizuje markę pod cytowalność przez modele językowe w ChatGPT, Claude i Gemini. Fundament jest podobny - autorytet, treści, źródła - natomiast warstwa wykonawcza wymaga innych taktyk: kapsuł treści, danych strukturalnych zsynchronizowanych z widoczną treścią, plików typu llms.txt i treści kategorii, z których retriever może cytować.
Czy mogę zrobić taki audyt sam?
Podstawowy pomiar tak, i metodę opisałem w sekcji 03 właśnie po to, żeby dało się ją powtórzyć: zestaw promptów pokrywających Twoją kategorię, trzy modele z wyszukiwaniem, zerojedynkowa metryka obecności marki. Wartość pracy z audytorem zaczyna się dalej - w interpretacji, dlaczego konkretny model Cię nie cytuje, z jakich źródeł korzysta w Twojej branży, w benchmarku konkurencji i w roadmapie zmian z priorytetami.
Dlaczego modele znają markę, a mimo to nie polecają jej w kategorii?
Bo na pytania kategorii („kto w Polsce robi X") modele z wyszukiwaniem odpowiadają ze źródeł zewnętrznych i treści kategorii, a nie z samego faktu, że marka istnieje i jest rozpoznawalna. Mój baseline pokazał to wprost: 100% w pytaniach brandowych i 0% w pytaniach kategorii AI Visibility. Naprawa polega na zbudowaniu treści kategorii, które retriever może zacytować - na własnej domenie i w źródłach zewnętrznych.
Ile trwa, zanim modele zauważą zmiany na stronie?
Uczciwie: pierwsze sygnały w warstwie wyszukiwania na żywo (np. tryb search w ChatGPT czy Gemini) widać po kilku tygodniach, pełne efekty w statycznej wiedzy modeli po kilku miesiącach do roku, zależnie od cyklu aktualizacji konkretnego modelu. Modele mają dwie warstwy danych i zmiany docierają do nich w różnym tempie. Dlatego mierzę co tydzień i raportuję w rytmie 30/60/90 dni, zamiast obiecywać szybkie efekty.
Czy pojedynczy test widoczności coś mówi?
Niewiele. Zapytaj model trzy razy o to samo, a dostaniesz trzy różne odpowiedzi, więc pojedynczy strzał nie ma wartości diagnostycznej. Znaczenie ma częstotliwość pojawiania się marki w serii zapytań, mierzona tą samą baterią promptów w regularnych odstępach. Marka obecna w 8 z 10 odpowiedzi jest realnie widoczna, a obecna w 1 z 10 to przypadek, nie pozycja.
Baseline zmierzony 3 lipca 2026, program zmian wdrożony 3-5 lipca 2026. Część druga tego artykułu, z wynikami trackera po 30, 60 i 90 dniach, ukaże się około sierpnia 2026 - niezależnie od tego, co pokażą liczby.
W razie pytań o audyt AI Visibility Twojej strony - jestem do dyspozycji.
Sprawdzę widoczność Twojej marki w ChatGPT, Claude i Gemini.
Ten sam warsztat, który opisałem wyżej, tylko pod Twoją kategorię i buyer persony. Snapshot to szybka diagnoza w 48 godzin, Deep Audit to pełny audyt z roadmapą na 90 dni. Zacznij od bezpłatnej 30-minutowej rozmowy.
